데이터 분석
타이타닉 데이터 분석하기
temporubato108
2024. 8. 28. 14:43
사용데이터
Titanic - Machine Learning from Disaster
https://www.kaggle.com/competitions/titanic
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
1. train.csv파일의 survived 데이터 시각화
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 설정
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf' # 폰트 경로
font_prop = fm.FontProperties(fname=font_path, size=14)
# 데이터 로드
data = pd.read_csv('train.csv')
# Survived 데이터 시각화
plt.figure(figsize=(8, 6))
data['Survived'].value_counts().plot(kind='bar', color=['skyblue', 'salmon'])
plt.title('타이타닉 생존자 수', fontproperties=font_prop)
plt.xlabel('생존 여부 (0 = 사망, 1 = 생존)', fontproperties=font_prop)
plt.ylabel('승객 수', fontproperties=font_prop)
plt.xticks(ticks=[0, 1], labels=['사망', '생존'], rotation=0, fontproperties=font_prop)
plt.grid(axis='y')
plt.show()
2. 생존여부(Survived)와 객실등급(Pclass)의 상관관계
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 설정
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf' # 폰트 경로
font_prop = fm.FontProperties(fname=font_path, size=14)
# 데이터 로드
data = pd.read_csv('train.csv')
# Survived와 Pclass 데이터 간의 관계 시각화
plt.figure(figsize=(10, 6))
data.groupby(['Pclass', 'Survived']).size().unstack().plot(kind='bar', color=['salmon', 'lightblue'], width=0.8)
plt.title('타이타닉 승객 생존 여부와 객실 등급(Pclass) 관계', fontproperties=font_prop)
plt.xlabel('객실 등급 (Pclass)', fontproperties=font_prop)
plt.ylabel('승객 수', fontproperties=font_prop)
plt.xticks(ticks=[0, 1, 2], labels=['1등급', '2등급', '3등급'], rotation=0, fontproperties=font_prop)
# 범례 설정
plt.legend(['사망', '생존'], title='생존 여부', prop=font_prop, title_fontproperties=font_prop, loc='upper right')
plt.grid(axis='y')
plt.show()
3. 생존여부(Survived)와 성별(Sex)의 상관관계
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 설정
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf' # 폰트 경로
font_prop = fm.FontProperties(fname=font_path, size=14)
# 데이터 로드
data = pd.read_csv('train.csv')
# Survived와 Sex 데이터 간의 관계 시각화
plt.figure(figsize=(10, 6))
data.groupby(['Sex', 'Survived']).size().unstack().plot(kind='bar', color=['salmon', 'lightblue'], width=0.8)
plt.title('타이타닉 승객 생존 여부와 성별(Sex) 관계', fontproperties=font_prop)
plt.xlabel('성별', fontproperties=font_prop)
plt.ylabel('승객 수', fontproperties=font_prop)
plt.xticks(ticks=[0, 1], labels=['여성', '남성'], rotation=0, fontproperties=font_prop)
# 범례 설정
plt.legend(['사망', '생존'], title='생존 여부', prop=font_prop, title_fontproperties=font_prop, loc='upper right')
plt.grid(axis='y')
plt.show()
4. 생존여부(Survived)와 나이(Age)의 상관관계
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.font_manager as fm
# 한글 폰트 설정
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf' # 폰트 경로
font_prop = fm.FontProperties(fname=font_path, size=14)
# 데이터 로드
data = pd.read_csv('train.csv')
# 나이가 결측값인 경우 제거
data = data.dropna(subset=['Age'])
# 나이에 따른 생존 여부 시각화
plt.figure(figsize=(12, 6))
sns.histplot(data=data, x='Age', hue='Survived', multiple='stack', bins=40, palette={0: 'salmon', 1: 'lightblue'}, kde = True, alpha=0.7)
plt.title('타이타닉 승객 생존 여부와 나이(Age) 관계', fontproperties=font_prop)
plt.xlabel('나이', fontproperties=font_prop)
plt.ylabel('승객 수', fontproperties=font_prop)
plt.legend(['생존', '사망'], title='생존 여부', prop=font_prop, title_fontproperties=font_prop)
plt.grid(axis='y')
plt.show()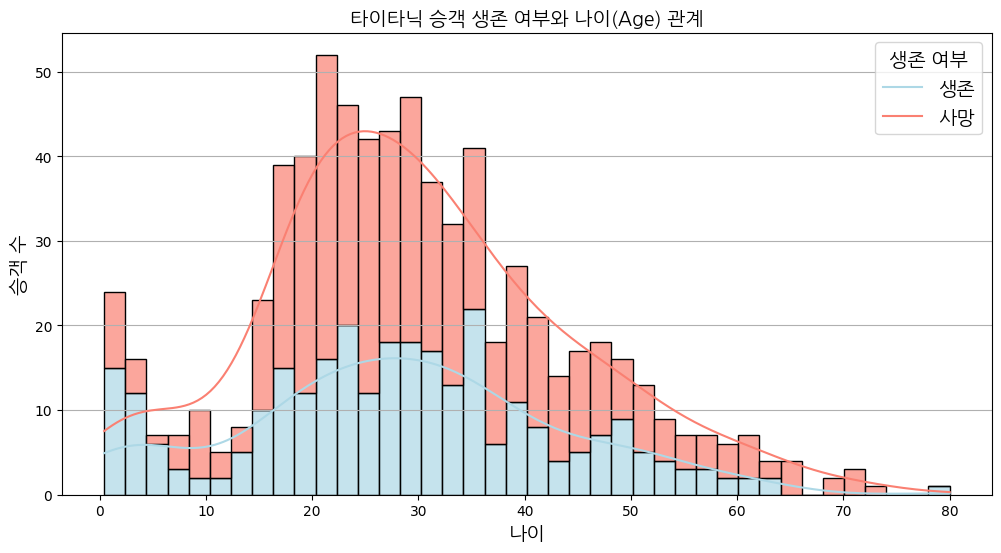
5. 생존여부(Survived)와 가족 수(SibSp + Parch)의 상관관계
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 설정
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf' # 폰트 경로
font_prop = fm.FontProperties(fname=font_path, size=14)
# 데이터 불러오기
data = pd.read_csv('train.csv')
# 가족 수(SibSp + Parch) 계산
data['FamilySize'] = data['SibSp'] + data['Parch']
# 생존률 계산
survival_rate = data.groupby('FamilySize')['Survived'].mean().reset_index()
# 시각화
plt.figure(figsize=(10, 6))
sns.barplot(data=survival_rate, x='FamilySize', y='Survived', palette='Set1')
plt.title('가족 수에 따른 생존률', fontproperties=font_prop)
plt.xlabel('가족 수 (SibSp + Parch)', fontproperties=font_prop)
plt.ylabel('생존률', fontproperties=font_prop)
plt.xticks(rotation=0)
plt.ylim(0, 1) # 생존률은 0에서 1 사이의 값으로 설정
plt.axhline(0.5, ls='--', color='red') # 50% 생존률 기준선 추가
plt.show()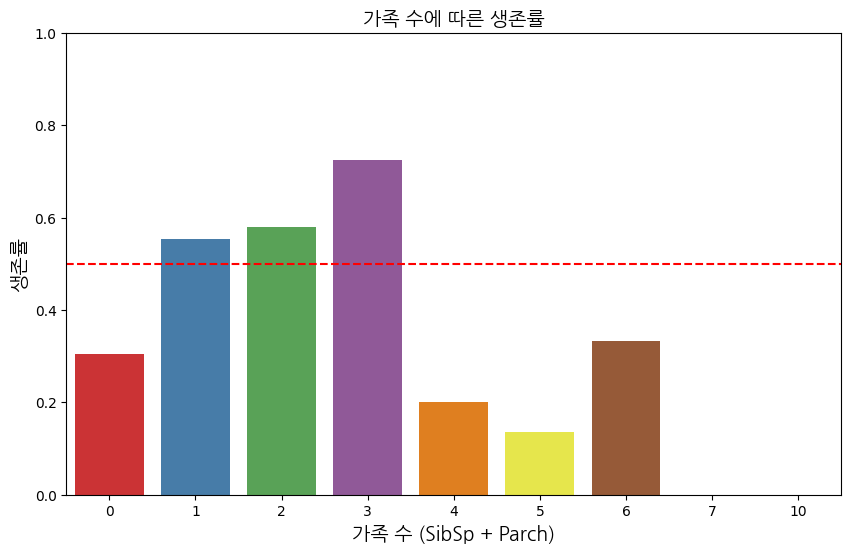
6. 생존여부(Survived)와 요금(Fare)의 상관관계
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 설정
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf' # 폰트 경로
font_prop = fm.FontProperties(fname=font_path, size=14)
# 데이터 불러오기
data = pd.read_csv('train.csv')
# Fare 데이터 로그 변환
data['Fare_log'] = np.log1p(data['Fare']) # log1p는 log(1+x)를 계산하는 함수
# 시각화
plt.figure(figsize=(10, 6))
sns.boxplot(x='Survived', y='Fare_log', data=data, palette='Set1').set(ylim=(0,10))
plt.title('생존 여부에 따른 요금(Fare) 로그 변환 분포', fontproperties=font_prop)
plt.xlabel('생존 여부 (0: 사망, 1: 생존)', fontproperties=font_prop)
plt.ylabel('로그 변환된 요금 (Fare_log)', fontproperties=font_prop)
plt.xticks(rotation=0)
plt.grid(True)
plt.show()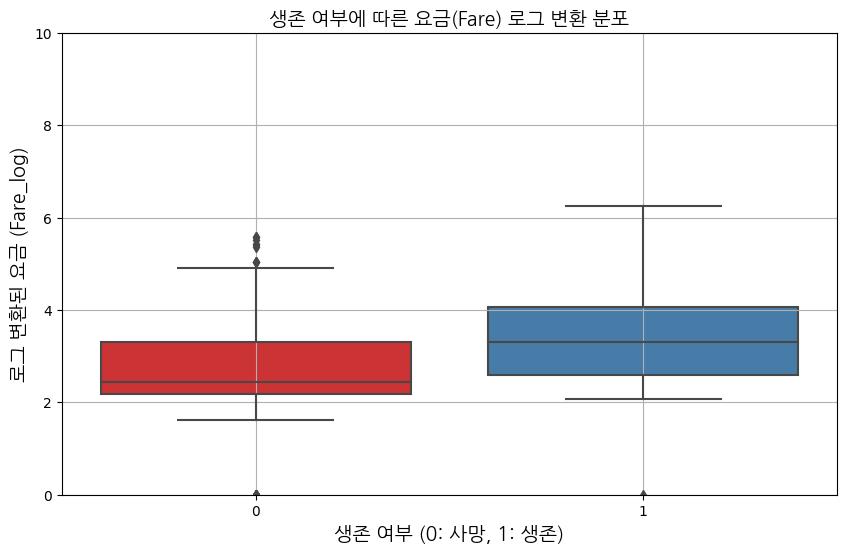
7. 생존여부(Survived)와 선실번호(Cabin)의 상관관계
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 설정
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf' # 폰트 경로
font_prop = fm.FontProperties(fname=font_path, size=14)
# 데이터 불러오기
data = pd.read_csv('train.csv')
# Cabin 데이터 전처리: 결측치 제거 및 첫 글자만 추출
data = data.dropna(subset=['Cabin']) # 결측치 제거
data['Cabin'] = data['Cabin'].str[0] # 각 Cabin의 첫 글자만 추출
# 생존률 계산
survival_rate = data.groupby('Cabin')['Survived'].mean().reset_index() # Cabin 별 생존률 계산
# 시각화
plt.figure(figsize=(10, 6))
sns.barplot(x='Cabin', y='Survived', data=survival_rate, palette='Set1') # 생존률을 y축으로 설정
plt.title('선실 번호(Cabin) 별 생존률', fontproperties=font_prop)
plt.xlabel('선실 번호(Cabin)', fontproperties=font_prop)
plt.ylabel('생존률', fontproperties=font_prop)
plt.xticks(rotation=0)
plt.grid(True)
plt.ylim(0, 1) # y축 범위를 0에서 1로 설정
plt.show()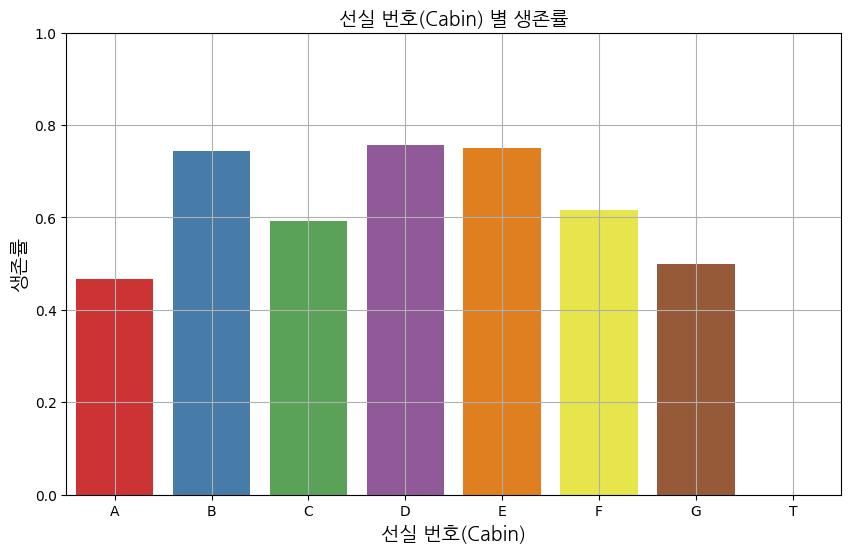
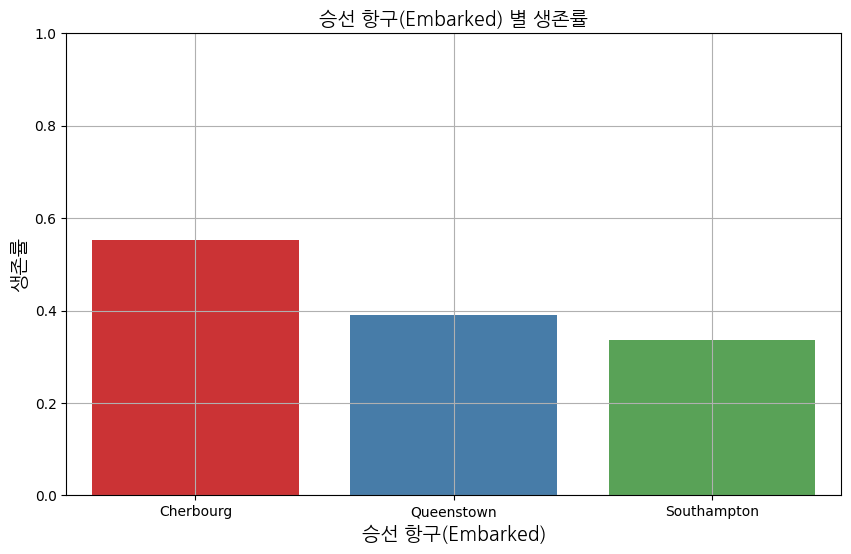
8. 생존여부(Survived)와 승선 항구(Embarked)의 상관관계
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 설정
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf' # 폰트 경로
font_prop = fm.FontProperties(fname=font_path, size=14)
# 데이터 불러오기
data = pd.read_csv('train.csv')
# Embarked 데이터 전처리: 결측치 제거
data = data.dropna(subset=['Embarked']) # 결측치 제거
# 생존률 계산
survival_rate = data.groupby('Embarked')['Survived'].mean().reset_index() # Embarked 별 생존률 계산
# 시각화
plt.figure(figsize=(10, 6))
sns.barplot(x='Embarked', y='Survived', data=survival_rate, palette='Set1') # 생존률을 y축으로 설정
plt.title('승선 항구(Embarked) 별 생존률', fontproperties=font_prop)
plt.xlabel('승선 항구(Embarked)', fontproperties=font_prop)
plt.ylabel('생존률', fontproperties=font_prop)
plt.xticks(ticks=[0, 1, 2], labels=['Cherbourg', 'Queenstown', 'Southampton'], rotation=0) # x축 레이블 수정
plt.grid(True)
plt.ylim(0, 1) # y축 범위를 0에서 1로 설정
plt.show()