wine 데이터셋을 활용한 혼동행렬 시각화
혼동행렬 시각화를 LLM를 사용해서 공부한 내용을 정리함.
전체 코드 중 시각화에 대한 부분만 다루었으며, 전체 코드는 파일로 첨부함.
1. 함수 정의 및 제목 설정:
title = ""
if normalize:
title = 'Normalized confusion matrix'
else:
title = 'Confusion matrix'
여기서는 normalize 매개변수를 확인하여 행렬을 정규화(normalization)할지 결정합니다. 정규화는 데이터의 범위를 조정하는 것을 말하는데, 여기서는 각 클래스별 예측 비율을 확인하는 용도입니다. 이 부분은 이해하기 쉬운 기초적인 개념이에요.
2. 클래스 이름 추출:
classes = classes[unique_labels(y_true, y_pred)]
y_true(실제 값)와 y_pred(예측 값)의 고유 라벨(클래스)을 추출해 혼동 행렬에 표시할 클래스들을 설정합니다. 기본적인 배열 처리지만, 조금 더 복잡한 배열 인덱싱을 이해해야 합니다.
3. 혼동 행렬 정규화:
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
정규화가 활성화되었을 때, 각 행의 합으로 각 요소를 나누어 비율로 변환하는 부분입니다. 여기서 np.newaxis를 활용하는 점은 약간 중급 개념이지만, 데이터 차원을 조정할 때 중요한 기법이에요.
4. 행렬 출력:
print(title, ":/n", cm)
혼동 행렬을 텍스트로 출력하는 코드로, 디버깅이나 중간 결과를 확인할 때 유용한 방식입니다.
5. 그래프 초기 설정:
fig, ax = plt.subplots()
im = ax.imshow(cm, interpolation='nearest', cmap=cmap)
ax.figure.colorbar(im, ax=ax)
여기서는 matplotlib를 이용해 그래프를 그릴 준비를 합니다. imshow는 이미지를 그릴 때 자주 사용하는 함수로, 혼동 행렬을 색으로 표현하는 그래프를 생성합니다. colorbar는 색의 강도를 나타내는 막대를 추가하는데, 이 부분은 시각화 관련 코드로 간단하게 이해할 수 있습니다.
6. 축 및 라벨 설정:
ax.set(xticks=np.arange(cm.shape[1]),
yticks=np.arange(cm.shape[0]),
xticklabels=classes, yticklabels=classes,
title=title,
ylabel='True label',
xlabel='Predicted label')
그래프의 축(x축, y축)과 라벨을 설정하는 부분입니다. 이때, xticks, yticks로 축의 위치를 설정하고, xticklabels, yticklabels로 클래스 이름을 축에 표시합니다.
7. 라벨 회전:
plt.setp(ax.get_xticklabels(), rotation=45, ha="right", rotation_mode="anchor")
x축의 라벨을 45도 회전시켜 더 잘 보이게 하는 코드입니다. plt.setp는 설정을 한 번에 적용할 수 있는 유용한 함수로, 코드의 가독성을 높이고, 반복적인 설정을 줄여줍니다.
ha="right"는 Matplotlib에서 텍스트의 수평 정렬(horizontal alignment)을 설정하는 옵션입니다. ha는 "horizontal alignment"의 약자로, 텍스트가 기준점에 대해 어떻게 정렬될지를 지정합니다.
- ha="right": 텍스트를 오른쪽으로 정렬합니다.
- ha="left": 텍스트를 왼쪽으로 정렬합니다.
- ha="center": 텍스트를 중앙으로 정렬합니다.
예를 들어, ha="right"를 사용하면 x축 레이블이 오른쪽 끝을 기준으로 정렬되어, 레이블이 겹치지 않고 깔끔하게 표시될 수 있습니다.
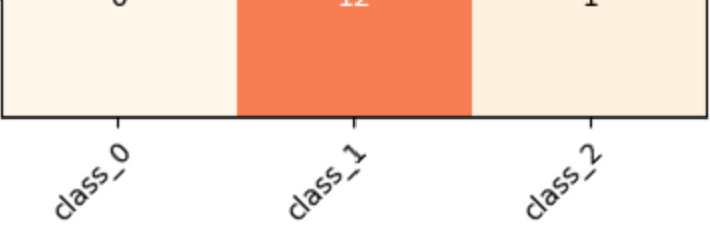

8. 혼동 행렬 값 표시:
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, format(cm[i, j], fmt),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
각 혼동 행렬의 값을 그래프 위에 직접 표시합니다. 여기서 fmt는 값의 포맷을 결정하는 변수인데, 정규화 여부에 따라 소수점 표시를 할지 정수로 표시할지를 정합니다. 이 부분은 조금 더 난이도가 높은 반복문과 조건부 색 설정을 포함하고 있습니다. cm.max() / 2.로 임계값을 설정해, 값이 클수록 하얀색, 작을수록 검은색으로 표시하는데, 시각적 가독성을 높이는 기법입니다.
9. 레이아웃 조정 및 그래프 출력:
fig.tight_layout()
plt.show()
마지막으로 그래프의 레이아웃을 자동으로 조정하고, 그래프를 출력하는 코드입니다. 시각화의 마지막 단계로, 어렵지 않게 이해할 수 있습니다.
10. 추가 질문에 대한 답변:
- Confusion Matrix 정규화 이유: Confusion matrix의 값은 절대값으로 표현되며, 각 클래스에 속한 샘플 수에 따라 값이 크게 달라질 수 있습니다. 정규화를 하면 각 클래스에 대한 상대적인 오류를 비교하기 쉽고, 각 클래스 간의 차이를 시각적으로 명확하게 표현할 수 있습니다. 즉, 데이터 양이 불균형할 때 정규화를 통해 각 클래스의 성능을 비교할 수 있는 장점을 얻습니다.
- classes = classes[unique_labels(y_true, y_pred)]: 이 코드는 y_true(실제값)과 y_pred(예측값)에서 나타나는 고유한 클래스 라벨들을 추출하는 역할을 합니다. unique_labels(y_true, y_pred)는 이 두 배열에서 고유한 라벨을 찾아 반환하는데, 그 결과에 맞춰 classes 배열을 필터링합니다. 이를 통해 실제 사용된 클래스들만을 confusion matrix에 표시하게 됩니다. 예를 들어, 클래스가 3개인데 실제로 예측에 사용된 라벨이 2개라면, 해당 2개의 클래스만 남깁니다.
- [:, np.newaxis] 설명: [:, np.newaxis]는 Numpy에서 배열의 차원을 확장할 때 사용합니다. 구체적으로, 1D 배열을 2D 배열로 변환하고 싶을 때 주로 사용됩니다. [:, np.newaxis]는 배열의 각 요소에 대해 새로운 축을 추가하여 차원을 확장합니다. 예를 들어, (n,) 형태의 1차원 배열을 (n, 1) 형태로 변경할 수 있습니다. 이는 특정 연산에서 차원 맞추기가 필요할 때 유용합니다.
11. 시각화 결과


코드 출처: Elice(https://24ictoc-d.elice.io/explore)